🧩 General365: Benchmarking General Reasoning in LLMs Across Diverse and Challenging Tasks
🏆 Leaderboard 🏆
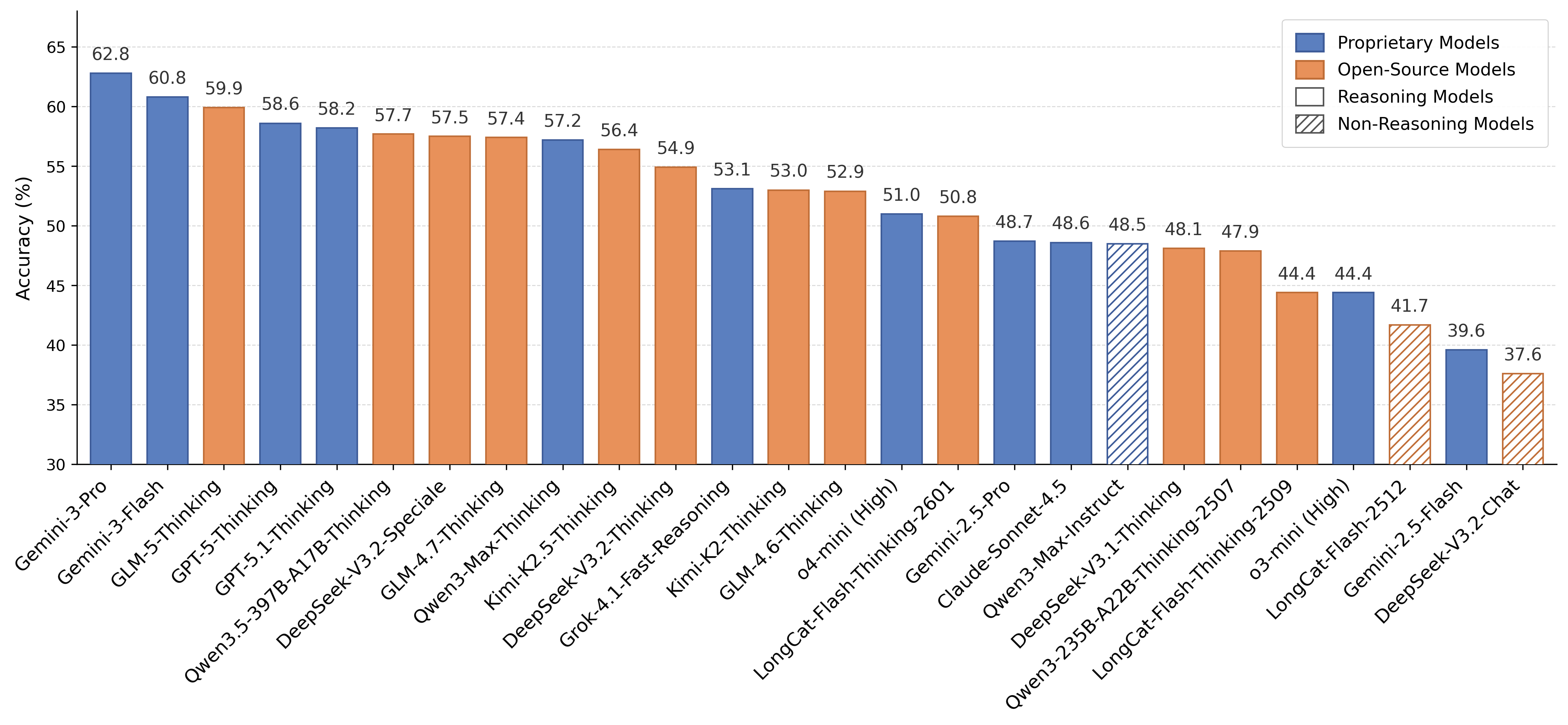
Note: To ensure the impartiality of the evaluation, we have released only half of the total questions. The remaining questions are maintained as a held-out test set to track potential data contamination within the open-source part. If you would like to add your model to the leaderboard on the full evaluation set, please feel free to contact us via Email or WeChat.
📝 Abstract 📝
Contemporary large language models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in specialized domains like mathematics and physics. However, their ability to generalize these reasoning skills to more general and broader contexts—often termed general reasoning—remains under-explored. Unlike domain-specific reasoning, general reasoning relies less on expert knowledge but still presents formidable reasoning challenges, such as complex constraints, nested logical branches, and semantic interference. To address this gap, we introduce General365, a benchmark specifically designed to assess general reasoning in LLMs. By restricting background knowledge to a K-12 level, General365 explicitly decouples reasoning from specialized expertise. The benchmark comprises 365 seed problems and 1,095 variant problems across eight categories, ensuring both high difficulty and diversity. Evaluations across 26 leading LLMs reveal that even the top-performing model achieves only 62.8% accuracy, in stark contrast to the near-perfect performances of LLMs in math and physics benchmarks. These results suggest that the reasoning abilities of current LLMs are heavily domain-dependent, leaving significant room for improvement in broader applications. We envision General365 as a catalyst for advancing LLM reasoning beyond domain-specific tasks toward robust, general-purpose real-world scenarios.
🌟 Challenge Categories & Construction Pipeline 🌟
A.Challenge Categories:To ensure high-level structural diversity and pinpoint the performance bottlenecks of current LLMs in general reasoning, we establish a conceptual taxonomy for the challenge covered by General365. Specifically, by synthesizing existing reasoning benchmarks and analyzing real-world inferential requirements, we have codified eight distinct challenge categories: Complex Constraints, Branching & Enumeration, Spatial & Temporal, Recursive & Backtracking, Semantic Interference, Implicit Information, Optimal Strategy and Probability & Uncertainty.
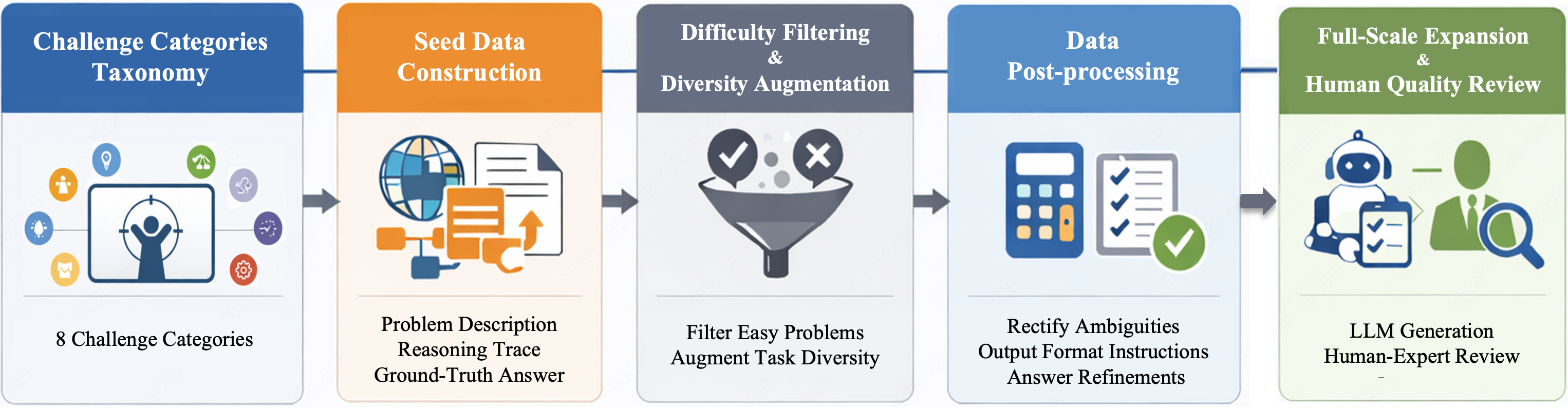
B.Construction Pipeline: Guided by the challenge categories taxonomy introduced above, we developed a multi-stage construction pipeline to ensure the diversity, complexity and quality of General365. The workflow consisted of four primary phases: (1) Seed Data Construction. (2) Difficulty Filtering & Diversity Augmentation. (3) Data Post-processing. (4) Full-scale Expansion & Human Quality Review.
📊 Dataset Statistics 📊
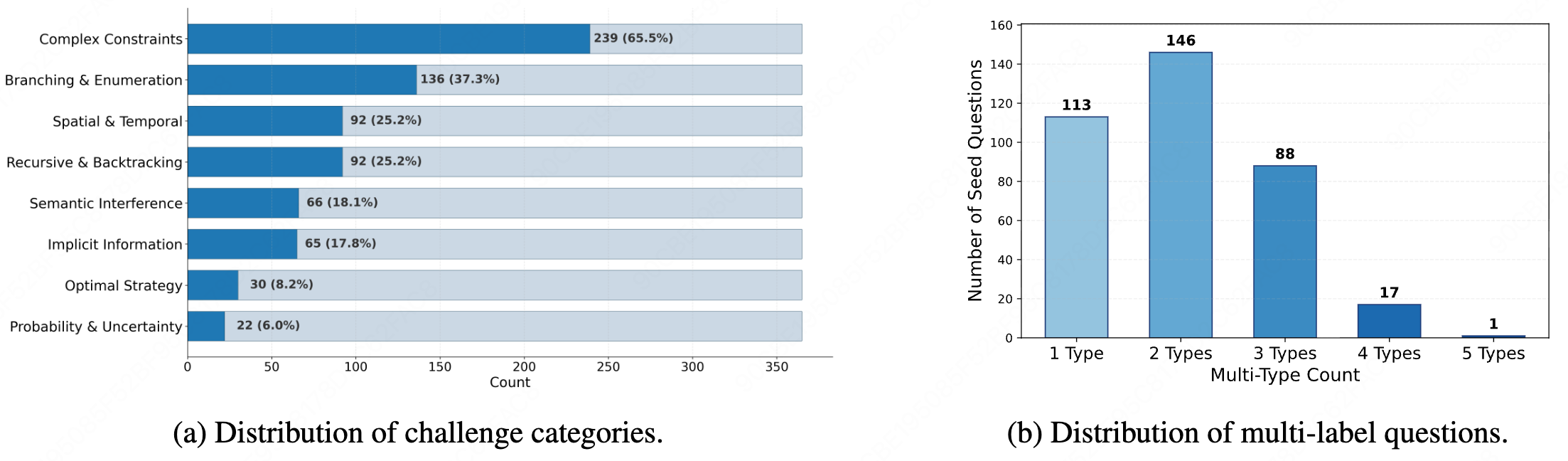
A.Distribution of challenge categories: Based on challenge categories taxonomy above, each seed problem in General365 is annotated with one or more challenge labels.
Figure (a) illustrates the overall distribution of challenge categories within General365
As shown, "Complex Constraints" emerges as the most predominant challenge, while "Probability & Uncertainty" accounts for the smallest proportion of the dataset.
B.Distribution of multi-label questions:
Figure (b) presents the distribution of multi-label instances.
Notably, nearly 70% of the problems are annotated with two or more challenge tags, further underscoring that General365 is characterized by high-difficulty, composite challenges rather than isolated reasoning tasks.
🔥 Main Results 🔥
| Rank | Models | Complex Constraints |
Branching &Enumeration |
Spatial &Temporal |
Recursive &Backtracking |
Semantic Interference |
Implicit Information |
Optimal Strategy |
Probability &Uncertainty |
Overall | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Thinking Models | ||||||||||||||
| 1 |  Gemini-3-Pro Gemini-3-Pro |
65.3% | 64.3% | 57.6% | 66.8% | 55.7% | 68.8% | 50.8% | 54.5% | 62.8% | ||||
| 2 | Gemini-3-Flash |
62.9% | 64.5% | 56.5% | 69.3% | 55.7% | 62.7% | 48.3% | 60.2% | 60.8% | ||||
| 3 |  GLM-5-Thinking GLM-5-Thinking |
63.5% | 69.1% | 52.9% | 68.2% | 49.2% | 55.4% | 51.7% | 56.8% | 59.9% | ||||
| 4 |  GPT-5-Thinking GPT-5-Thinking |
61.7% | 65.4% | 48.6% | 65.2% | 57.2% | 58.5% | 47.5% | 59.1% | 58.6% | ||||
| 5 | GPT-5.1-Thinking |
61.1% | 62.9% | 48.6% | 64.4% | 53.4% | 61.5% | 47.5% | 47.7% | 58.2% | ||||
| 6 |  Qwen3.5-397B-A17B-Thinking Qwen3.5-397B-A17B-Thinking |
60.1% | 62.1% | 50.0% | 67.9% | 50.8% | 59.2% | 43.3% | 59.1% | 57.7% | ||||
| 7 |  DeepSeek-V3.2-Speciale DeepSeek-V3.2-Speciale |
60.4% | 63.6% | 52.2% | 65.8% | 51.5% | 51.9% | 50.0% | 55.7% | 57.5% | ||||
| 8 | GLM-4.7-Thinking |
59.1% | 63.8% | 49.7% | 68.8% | 49.6% | 57.3% | 49.2% | 58.0% | 57.4% | ||||
| 9 | Qwen3-Max-Thinking |
59.4% | 65.3% | 51.4% | 66.8% | 46.2% | 60.0% | 48.3% | 53.4% | 57.2% | ||||
| 10 |  Kimi-K2.5-Thinking Kimi-K2.5-Thinking |
60.0% | 64.3% | 46.5% | 65.2% | 47.0% | 54.6% | 48.3% | 54.5% | 56.4% | ||||
| 11 | DeepSeek-V3.2-Thinking |
57.1% | 62.5% | 45.1% | 64.9% | 49.2% | 52.3% | 48.3% | 53.4% | 54.9% | ||||
| 12 |  Grok-4.1-Fast-Reasoning Grok-4.1-Fast-Reasoning |
56.6% | 59.9% | 43.8% | 62.5% | 50.8% | 50.0% | 39.2% | 46.6% | 53.1% | ||||
| 13 | Kimi-K2-Thinking |
54.9% | 61.9% | 44.6% | 62.5% | 42.8% | 53.1% | 46.7% | 52.3% | 53.0% | ||||
| 14 | GLM-4.6-Thinking |
57.2% | 59.9% | 40.8% | 64.1% | 48.5% | 55.4% | 38.3% | 43.2% | 52.9% | ||||
| 15 | o4-mini |
54.2% | 57.7% | 38.6% | 62.8% | 45.5% | 53.5% | 40.8% | 47.7% | 51.0% | ||||
| 16 |  LongCat-Flash-Thinking-2601 LongCat-Flash-Thinking-2601 |
54.1% | 61.4% | 38.3% | 59.5% | 45.1% | 46.2% | 39.2% | 51.1% | 50.8% | ||||
| 17 | Gemini-2.5-Pro |
50.9% | 56.1% | 35.9% | 57.6% | 48.1% | 48.1% | 34.2% | 44.3% | 48.7% | ||||
| 18 |  Claude-Sonnet-4.5 Claude-Sonnet-4.5 |
51.9% | 55.7% | 37.2% | 58.2% | 47.3% | 47.7% | 37.5% | 35.2% | 48.6% | ||||
| 19 | DeepSeek-V3.1-Thinking |
51.3% | 56.8% | 38.3% | 58.4% | 43.6% | 42.3% | 45.8% | 50.0% | 48.1% | ||||
| 20 | Qwen3-235B-Thinking-2507 |
50.8% | 55.1% | 32.3% | 60.9% | 49.2% | 46.5% | 41.7% | 45.5% | 47.9% | ||||
| 21 | LongCat-Flash-Thinking-2509 |
48.5% | 54.2% | 30.7% | 54.3% | 44.7% | 37.3% | 38.3% | 39.8% | 44.4% | ||||
| 22 | o3-mini |
47.4% | 51.1% | 32.9% | 54.6% | 38.6% | 47.3% | 28.3% | 30.7% | 44.4% | ||||
| 23 | Gemini-2.5-Flash |
42.8% | 46.5% | 28.3% | 47.8% | 35.6% | 33.8% | 35.8% | 34.1% | 39.6% | ||||
| Chat Models | ||||||||||||||
| 1 | Qwen3-Max-Instruct |
52.0% | 56.3% | 33.2% | 58.2% | 47.7% | 48.1% | 40.8% | 47.7% | 48.5% | ||||
| 2 | LongCat-Flash-2512 |
45.3% | 56.3% | 26.6% | 57.6% | 40.9% | 34.6% | 27.5% | 44.3% | 41.7% | ||||
| 3 | DeepSeek-V3.2-Chat |
40.7% | 46.9% | 26.1% | 50.3% | 37.1% | 29.6% | 22.5% | 35.2% | 37.6% | ||||
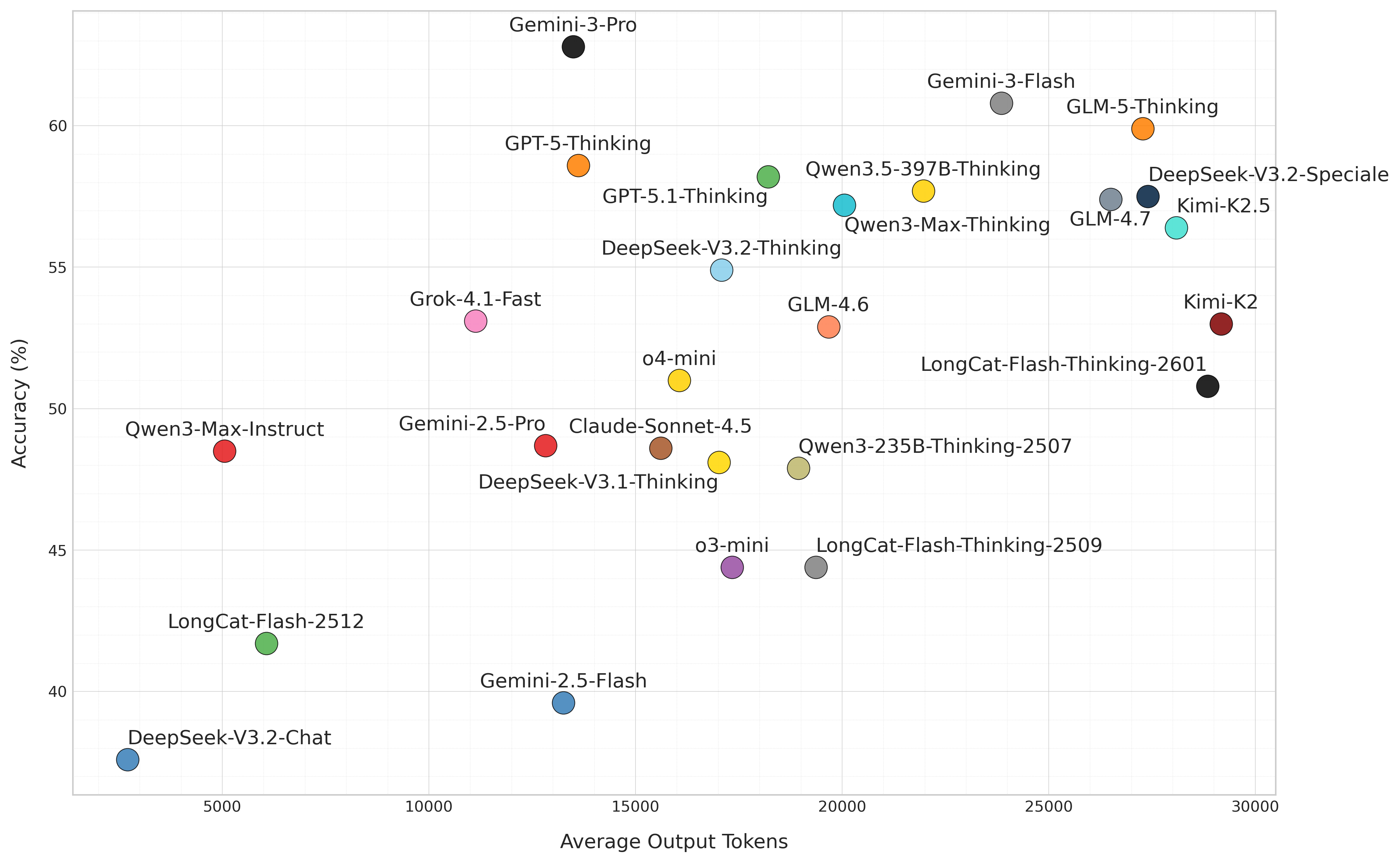
⚡️ Token Efficiency ⚡️
🔮 Validation of Diversity 🔮
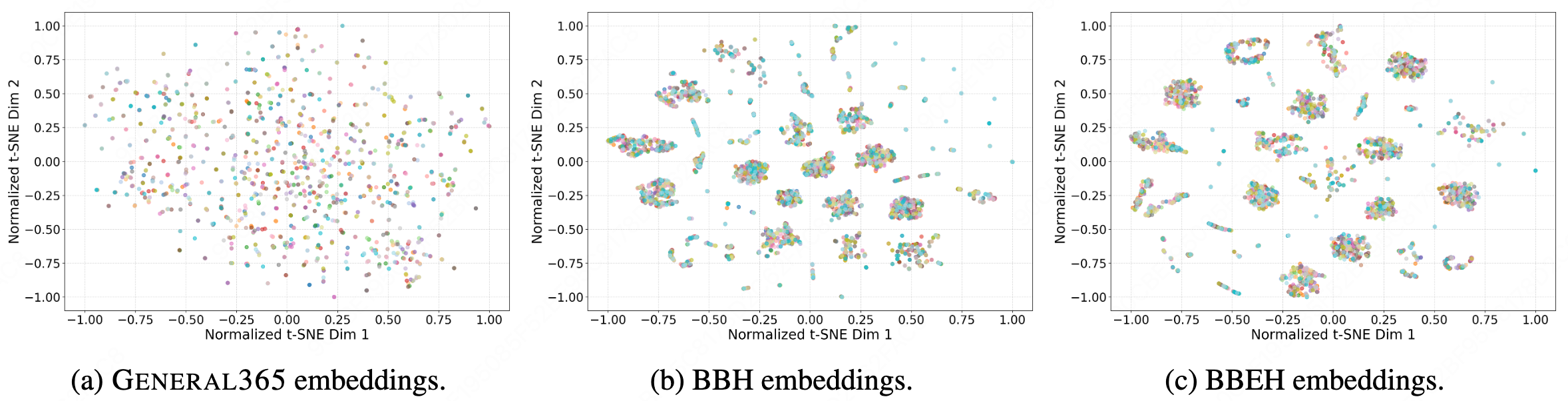
A.Qualitative Analysis of Semantic Space Coverage: To qualitatively assess the semantic breadth and distributional characteristics of General365, we project high-dimensional query embeddings into a 2D manifold. Specifically, we leverage the text-embedding-ada-002 model to encode queries into 1536-dimensional vectors, followed by t-SNE (Perplexity=30) for dimensionality reduction. For visual clarity, coordinates are normalized to the range [−1, 1]. As illustrated, General365 exhibits a substantially more uniform and expansive distribution across the semantic space compared to existing benchmarks. In contrast, BBH and BBEH manifest significant "local collapse," forming isolated, high-density clusters. This phenomenon suggests that while these benchmarks contain numerous samples, they are often confined to a narrow set of linguistic templates or logical skeletons. Conversely, the spatial dispersion of General365 underscores the efficacy of our high-quality seed strategy, where human-curated seed instances ensure semantic independence and minimize redundancy at the source.
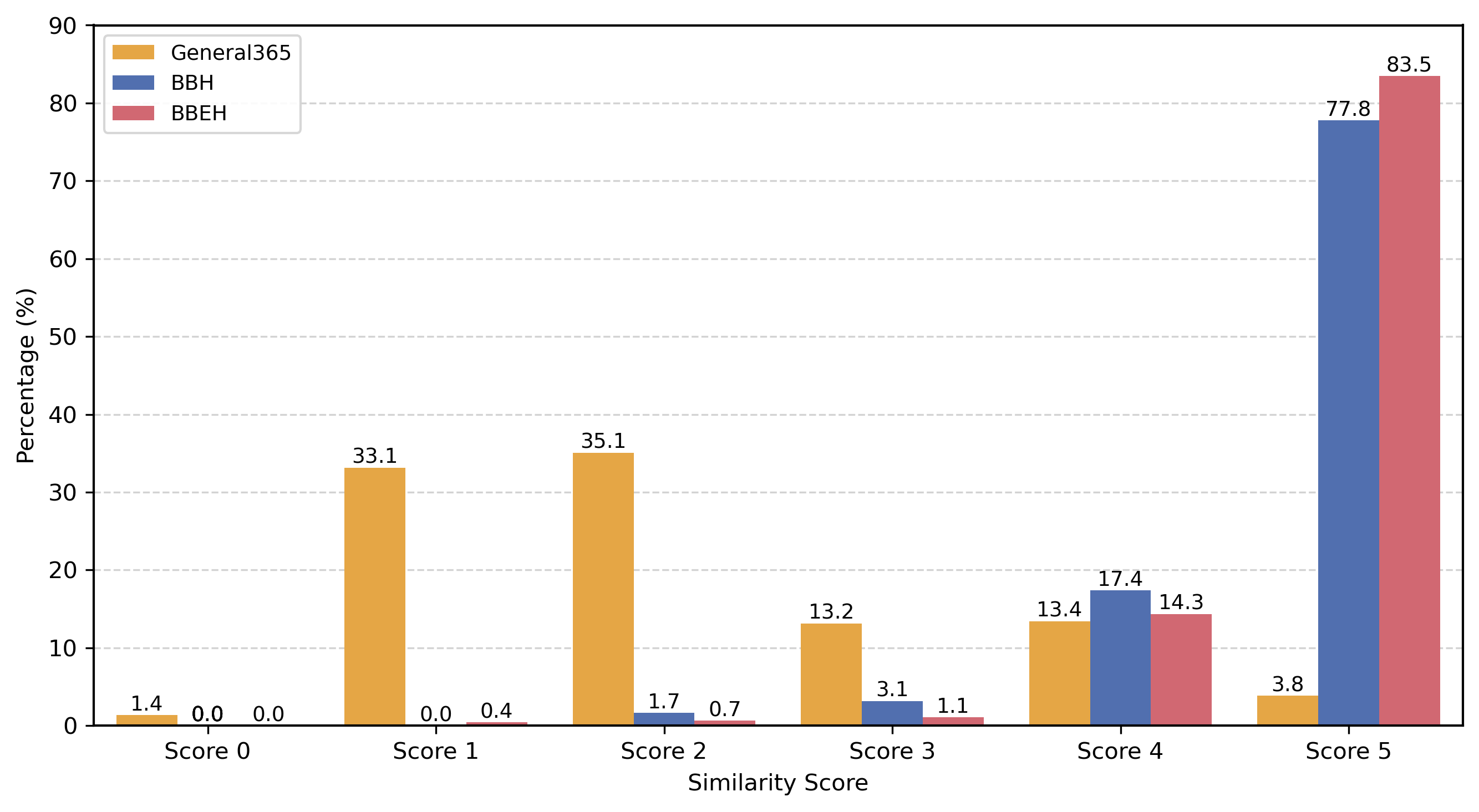
B.Quantitative Analysis of LLM-based Reasoning Similarity Scoring: To rigorously quantify the logical redundancy within the benchmarks, we propose a pairwise similarity scoring method. Unlike qualitative visualization, this approach deconstructs the underlying reasoning primitives and logic evolution of task instances. Specifically, for each problem TA in General365, we retrieve its nearest neighbor TB in the embedding space to identify the most semantically similar candidate. Then we employ Gemini-3-Pro as an expert evaluator to conduct a deep comparison of the triplets (Problem, CoT, Final Answer) for each pair. The similarity is quantified on a scale of 0 to 5, where 0 denotes total logical independence and 5 indicates essentially identical reasoning skeletons.
BibTeX
Coming Soon!